
Un paso más allá de la ciberseguridad
Obtén tu certificación para comercios PCI SAQ y protege los datos de tus clientes
Cumple con el estándar de seguridad de datos de la industria de tarjetas de pago (PCI DSS).
Quiero certificarme
vSOC ThreatGuard+

Por menos de lo que te cuesta tomarte un café al día protégete frente al temido ransomware, al robo de información confidencial y evita así posibles sanciones y demandas.
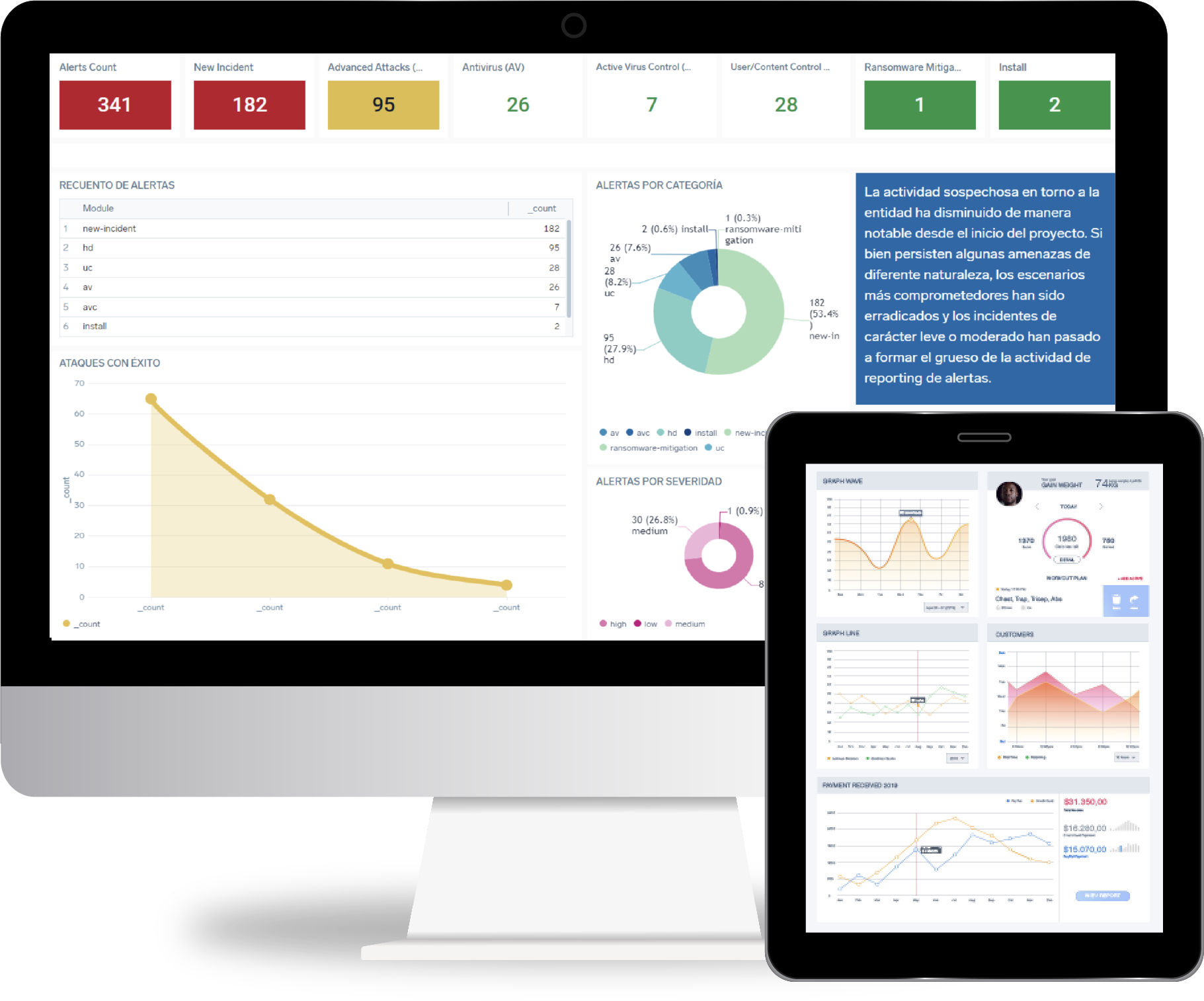
El primer SOC Virtual especializado en PCI 4.0
Apoyamos a nuestros clientes para crear y mantener una operación segura y rentable a través del cumplimiento de normativas y certificaciones PCI DSS.
Quiero saber másLa Ciberinteligencia, una actividad capital
Esta perspectiva global y profunda del panorama de seguridad capacita a nuestros clientes para tomar decisiones informadas y proactivas en la protección de sus activos digitales.

¿Cómo protegemos tu empresa de manera integral?
La mayoría de los dashboard presentan demasiada información. Nosotros te mostramos solo lo que necesitas.

Prevención de Fraude
Consultoría
Implantación de sistemas
Formación
Operación de plataformas
Data Science

Ciberseguridad
Hacking Ético
Pentesting
Análisis forense
Análisis y detección de fraude
Threat Hunting

Ciberinteligencia
Detección y cierre de phishing
Cybersquating
Análisis Forense
Benchmarking
Identificación de amenazas
ACADEMIA
¿Sabías que el 85% de las compañías españolas ha sufrido un ciberataque en el último año?
El error humano y la falta de concienciación en materia de seguridad se presentan hoy en día como el riesgo más importante para sus empresas. Te ayudamos a solucionarlo.
Quiero saber másActualidad en BOTECH
Últimas noticias destacadas de Ciberseguridad.

Tácticas Ciberseguras para Tu Equipo Estrella

En marzo entra en vigor PCI DSS 4.0: Todo lo que necesitas saber al respecto

Desde BOTECH, gracias por la confianza en 2023

¡BOTECH evoluciona! Te contamos todo sobre nuestra nueva identidad corporativa
Únete a nosotros

Si quieres formar parte de una compañía en pleno crecimiento y expansión, te brindamos la oportunidad de desarrollar tu carrera profesional con nosotros.
Socios con los que trabajamos
Estos son algunos de los aliados estratégicos de BOTECH.

Contacta con nosotros
¡Queremos saber de ti! Escríbenos a info@botech.info o completa este formulario y nos pondremos en contacto contigo.